
Indexing Obsidian.md
Some preliminary thoughts
Today, I wanted to briefly chat about what I have been working on over the last few days. I have been developing a custom ontology for the Unknown Ottawa project, which intends to create an accessible database of pre-contact and historical material culture held at the NCC. The ontology will combine Dublin Core, Getty, FOAF, and some custom vocabularies to create a Linked Open Data (LOD) repository using Omeka S and Borealis. After some tinkering around and research, I am finally moving forward with the vocabulary for the project and intend to connect Omeka S and Borealis via an API key to allow Omeka to import all the data. I think this will need to be done in chunks, as the CSV contains around 700 items. My other concern about the data and how we identify them in Borealis is promoting ‘Data Quality’, and inclusive language. In other words, ensuring that the database uses archaeological scientific language and the traditional knowledge/language of the Indigenous peoples whose material culture we are documenting. Serious considerations about post-colonial approaches for documenting this data and the material culture must be considered cautiously and openly with local Indigenous communities. Having Indigenous material culture thrown into an open-access database reeks of digital neo-colonialism. That said, we are in contact with the local communities regarding this project. For more on the project, visit the Unknown Ottawa website.
Developing a LOD for the Unknown Ottawa project had me reconsider how I document my notes in Obsidian and how these notes are searchable by me and the public via the Rogue History Notes open-access notebook. After reading a blog post by Jason Heppler on Obsidian, I decided to explore the Johnny.Decimal (JD) system, which Heppler links to in his blog. The JD system uses four-digit IDs called JDex to help organize notes, files, and life. It’s basically the Dewey-decimal system simplified. The system uses 10 ‘Areas’, each with 10 ‘Categories’ that can have up to 100 IDs. This JDex has some tangible uses for Obsidian. In theory, if applied to an Obsidian vault, an individual can house up to 10,000 notes. Considering Kansa and Kansa's (2022) arguments on promoting data quality, I’ve been using the foundations of the JD system to build an index for my Obsidian vault. A system that researchers can easily implement and apply to their work.
Kansa & Kansa effectively argue the importance of identifiers (ie, Locus, Date, Material, Type, etc.) for the (re)use of archaeological datasets. The article's importance is not that identifiers need to be consistent and unique, but rather that interdisciplinary collaboration is required in order to create manageable and effective identifiers to promote cross-disciplinary use and re-use of datasets to ensure constructive analysis. Since archaeology is a destructive discipline, data recording must be both critical and diligent in its methods to preserve the highest quality data for (re)use. In this spirit, I have been continuously reassessing how I identify my notes and files in Obsidian for publication on the Rogue History Notes OAN.
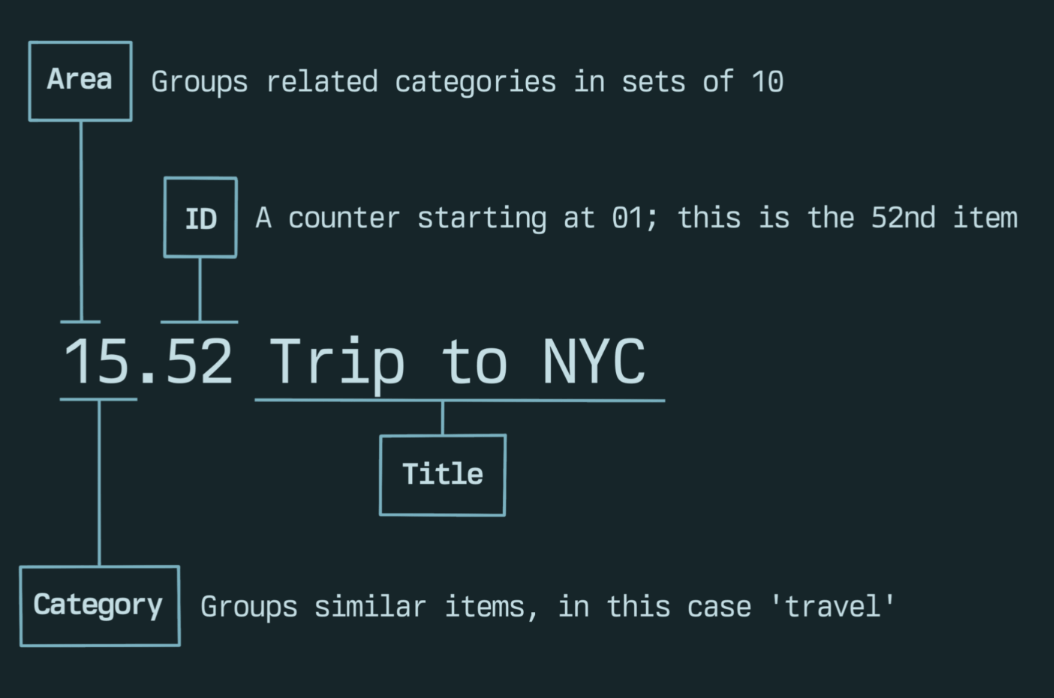
Fig. 1. JDex ID Breakdown
Fig. 2. Image made with Obsidian.md Canvas plugin.
In the past, I used various methods to construct IDs in my vault. Initially, I used simple titles that could be any length or topic, i.e., ‘Identifier’, ‘Dark Data’, ‘Stop Using Byzantine’, etc. I decided to try the Zettelkasten system, which uses a thematic-based numeric formulation. I implemented a dating schema for my pseudo-Zettelkasten system to highlight when a note was created and its rank on that day. For example, 20250605.03 would tell me and you that this note was created on June 5th, 2025 and is the 3rd note for that day (Fig. 4). The schema used [[wikis]] and #tags to help build links to other notes, which are searchable using Obsidian’s traditional search options or the more robust Omnisearch plugin (which I highly recommend installing). My objective for this form of Zettelkasten was to force myself to consider, more intellectually, how I would link my notes, instead of having notes populated in the wiki brackets as I typed, which led to haphazard and unmeaningful connections at times. A significant problem with this approach was that this method did not have a thematic numerical element, making it challenging to search notes based on themes—one of Zettelkasten’s core elements.

Fig. 3. Area, Category, and Sub-Category.
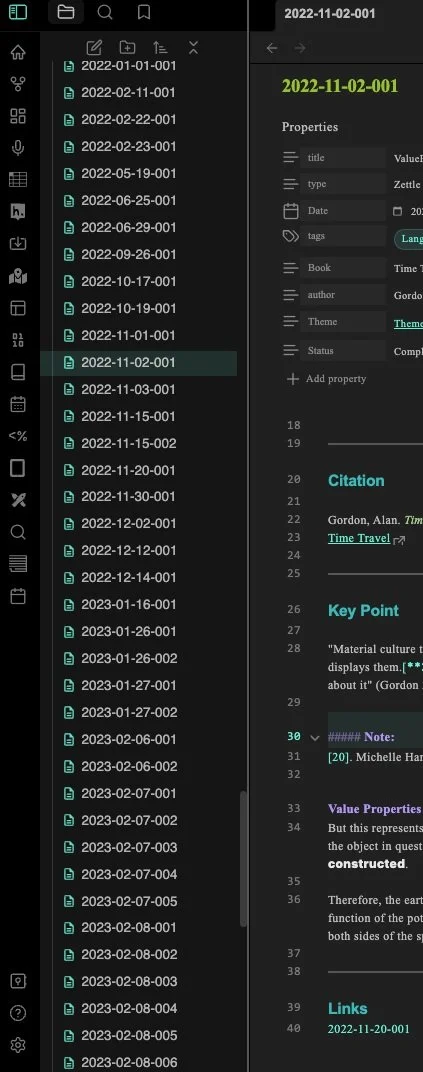
Fig. 4. Old ambiguous numerical identifier system.
You may be asking why I am using numbers again. For my system, I am using a four-digit ID with a title. The aim is to make notes easier for the public to search while providing a thematic-numerical system that can be queried. Time will only tell if such a system is successful. For example, ‘18.01 Wicked Problems’ is a note about what Wicked Problems are and how Byzantine studies are rife with them (in my humble opinion). The 1 represents the Area ‘Research’, 8 represents the ‘Category’ Theory & method, and the 01 is the note identifier in the category appended with the note title ‘Wicked Problems’ (Fig. 2). I hope that having a title alongside a numerical identifier will make the note more…enticing/accessible for the public, while I use the numerical indexing to create a more simplistic and navigable database of my research notes, projects and all the other tidbits in my vault. The index system I am developing is not entirely functional at the moment, nor is it a permanent solution. It’s a trial by fire. I am playing around with the numbers, per se — did I use that correctly?
Despite the potential of having 10,000 notes in a vault, the framework for 100 notes per category is not practical for any scholarly research. The reason for this is that some categories can proliferate notes, while others can be stagnant. It really is a matter of what you are researching at any given time. For my vault, category ‘18.00 Theory & Method’ currently has the most research notes. However, ‘52.40 Data’ ( a sub-category of ‘52.00 Inhabiting Byzantine Athens’, which holds individual files of coins I am studying from the Agora in Athens) has the highest number of files, currently at 308 and climbing. ‘52.40 Data’ is a secondary category within a category — Something the original JDex system shies away from. I expect these categories and secondary categories to change as my research progresses and as I process the many fleeting notes in my inbox. Approaching a category surpassing one hundred notes has a simple solution—keep adding digits, e.g., 18.99, 18.100, 18.101… Again, an approach JDex avoids. But I am still pondering whether I should develop secondary categories for my research notes, a possible unrewarding task. Moreover, the nomenclature of the ‘Areas’ and ‘Categories’ needs further consideration (the term Area rubs me the wrong way). Either way, the foundational principles of the JDex system appear to fit what I am looking for. I guess only time will tell.