More Roman Coins and Obsidian.md
Plugins and Templates
In a recent Xlab post on Qualitative Analysis of Social Media Posts, Dr. Shawn Graham shared how Obsidian.md was used to create a qualitative analysis environment for identifying prominent themes through close readings of social media posts. The project borrows from Ryan J. A. Murphy's Integrated Qualitative Analysis Environment. I've briefly discussed Mr. Murphy's work fulcra.design in a previous post. My interest in this method of analysis parallels Dr. Graham's. However, as I’ve discussed before, I want to explore the viability of Obsidian for blending qualitative and quantitative analysis of coins with particular attention to wear-use analysis and what types of knowledge visualization can be produced from the program. I have started the process of turning my Obsidian vault into a pseudo-database manager for numismatic analysis.

RTI software. Normals Visualization
My research on wear-use analysis began with using reflectance transformation imaging (RTI). Despite the technology's potential, the software could be more convenient and modern. New software development is ongoing but has its bugs. Thus, this approach for my research is stalled for now. Additionally, I have been increasingly interested in the viability of photogrammetry and (as readers of my blog know), I have been consumed by Obsidian.md's potential for knowledge visualization and to help scholars perform their research in a stable, open-sourced, future-proof software where data documented in markdown language can be stored and accessed without fear of proprietary ownership or gatekeeping, i.e. who is 'allowed' to access the data and who isn't. Ethan Gruber broadly touches on numismatic gatekeeping in his article "The Fralin Numismatic Collection: Ten Years Later." Obsidian has a large community of users who continually develop the software with many useful plugins. The Discord channel is buzzing with ideas and collaboration, but what does this all mean for database management?
First, I want to clarify that Obsidian will not provide all the resources you need to research. However, with the ever-expanding quantity of community-developed plugins available for Obsidian users, the software's potential is encouraging. Secondly, Obsidian is designed to be entirely malleable for your knowledge management needs and allows individuals to input their data into a simple plain-text language any computer can read. Plugins like Dataview and DBfolder (found in settings/community plugins/browse) allow you to import and query data in customizable ways for your research goals. The DBfolder plugin simplifies creating or importing CSV files, while Dataview enables you to query the data in your vault. For types of queries that you can make, click here. The query language is simple and easy to learn. For those who do code, DataviewJS (javascript) can be used to create more complex queries and in-line code. Furthermore, as Graham has demonstrated, python can be implemented into Obsidian. I don't want to be a maximalist, but endless possibilities exist. Therefore, Obsidian is my horse to bet on, and I placed all my chips on this stallion.
Proprietary database management software is designed to store large quantities of complex data and is more efficient in managing extensive coin collections held at museums and universities. These programs have the computing power to query and analyze tens of thousands of coins that are housed in major museums like the British Museum (London), the American Numismatic Society (New York), Dumbarton Oaks (Washington D.C) or the Stoa of Attalos (Athens). Furthermore, digitizing these collections and creating stable and uniform identifiers takes time, money, and sometimes political will. While physical access to these collections can be challenging to obtain, digital access can be just as problematic for the uninitiated.

My Ph.D. case study. The Nickle Galleries, University of Calgary.
Despite the efforts of international projects like nomisma.org, which promotes linked open data (LOD) with stable Uniform Resource Identifiers (URIs) between large numismatic institutions, not all scholars can access the data in a meaningful way that benefits their research. Researchers can be constrained if unfamiliar with these programs' languages, UI (user interface), and identifiers (how to query particular data types via labels/names/IDs. You get the idea). Creating queries that produce the researcher's desired results can be daunting and frustrating. I speak from experience. Therefore, nomisma.org may discourage rather than promote collaboration if you are a scholar or coin collector unfamiliar with the more technical side of database management and how to use query language like SPARQL to fetch data. To be clear, this is not to disparage, downplay or minimize the contributions of nomisma.org or organizations like the American Numismatic Society (ANS), which have and continue to contribute significantly to the field of numismatics. The ANS has fantastic resources for coin enthusiasts at all levels. Nomisma is more academically focused for those who specialize in numismatics.
Nevertheless, these organizations and projects have advanced digital accessibility to ancient and medieval coins via LOD in ways that scholars could not fathom fifty years ago. Still, the learning curve can be steep for individuals like myself who are dipping their toes into this blossoming field developing at breakneck speeds. Moreover, LOD is not the same as open-access, but that is a topic for another post. So, as an alternative for those who wish to create their personalized database management system, I suggest you explore Obsidian.md. For my research, I am inputting hundreds of coins into a simple template that uses the properties (metadata) feature to allow simple querying of files. The key is to provide a unique identifier for each entry when a note is created in the data folder. For my case study, the identifier is the inventory number where the coin is housed at the Stoa of Atalos in Athens, Greece (e.g. N22234, N22367). Each note contains a properties template I fill in with all the necessary data about a particular coin. See figs. 1.1
The properties UI can be adapted to the data type you input (text, list, number, checkbox, date, and date & time). This allows for easy-to-use customization and querying. However, you can also choose source mode and use the traditional YAML header for your metadata. At this point, I have yet to assess which is the more functional of the two. See figs. 1.2 and 1.3.
Below is an example of a simple Dataview query. Figure 1.4 demonstrates what the output looks like.

Dataview query in Obsidian.md. The ``` identify a code block
The first line of the query tells Dataview (DV) to create a table using the specified properties metadata and to rename them as specified. I've kept the property names the same except for the first field, where I renamed File to Title. The following line tells DV to pull data from a specific folder, e.g., "Inbox," and the third line tells DV only to grab files that contain an "incomplete" status property and a "high" priority property. The last line tells DV to list them in descending order according to date, i.e. most recent to oldest. For the Agora coin database, such queries will be beneficial for finding coins with particular qualities, such as a quantified wear/corrosion level. Again, the above is a basic query, but as you develop your Dataview and DataviewJS query language and knowledge skillset, the researcher's data analysis possibilities become...dare I say, infinite.
However, I noticed a hiccup/drawback when inputting all this data into Obsidian. It can drastically slow the software down, mainly if you use a single vault to store all your files. This can be somewhat circumvented by creating individual vaults for your projects. Now, this goes against the original intent of Obsidian: to be a second brain—a singular repository for your knowledge management needs. I don't want a second brain; I need many brains. Creating additional vaults to store data independently from other vaults will not solve the lag problem with large data sets, but it may help. With the above in mind, I would be curious to hear from other scholars using Obsidian with Dataview and DBfolder for their research and how their experience has been thus far.
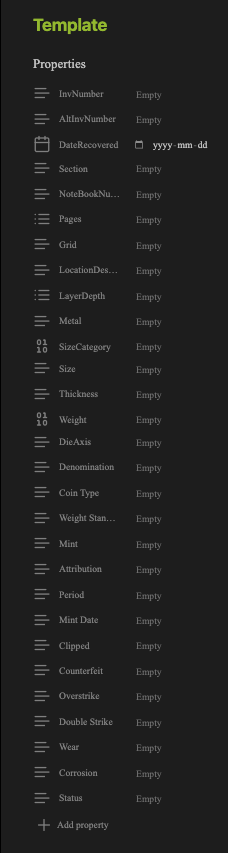
Fig. 1.1

Fig. 1.2

Fig. 1.3

Fig. 1.4